AIは今、
手書きを「読む」のではなく、
「理解する」。
homulaのDocument AI Agentは、最新マルチモーダルLLMの文書理解能力を活用し、手書き・スキャン・複雑レイアウトを含む帳票・文書の読み取りから転記・照合・承認フローまでをAIエージェントが自律実行する、エンタープライズ向けエンドツーエンド文書処理サービスです。
「AIに手書きは無理」は、もう過去の話です。請求書・発注書・契約書・手書き申請書・検査帳票など幅広い文書種別に対応。最短2週間でPoC開始。
DOCUMENT AI AGENT PIPELINE
従来OCRは②〜③まで / homulaは②〜⑦をAIエージェントが自律実行
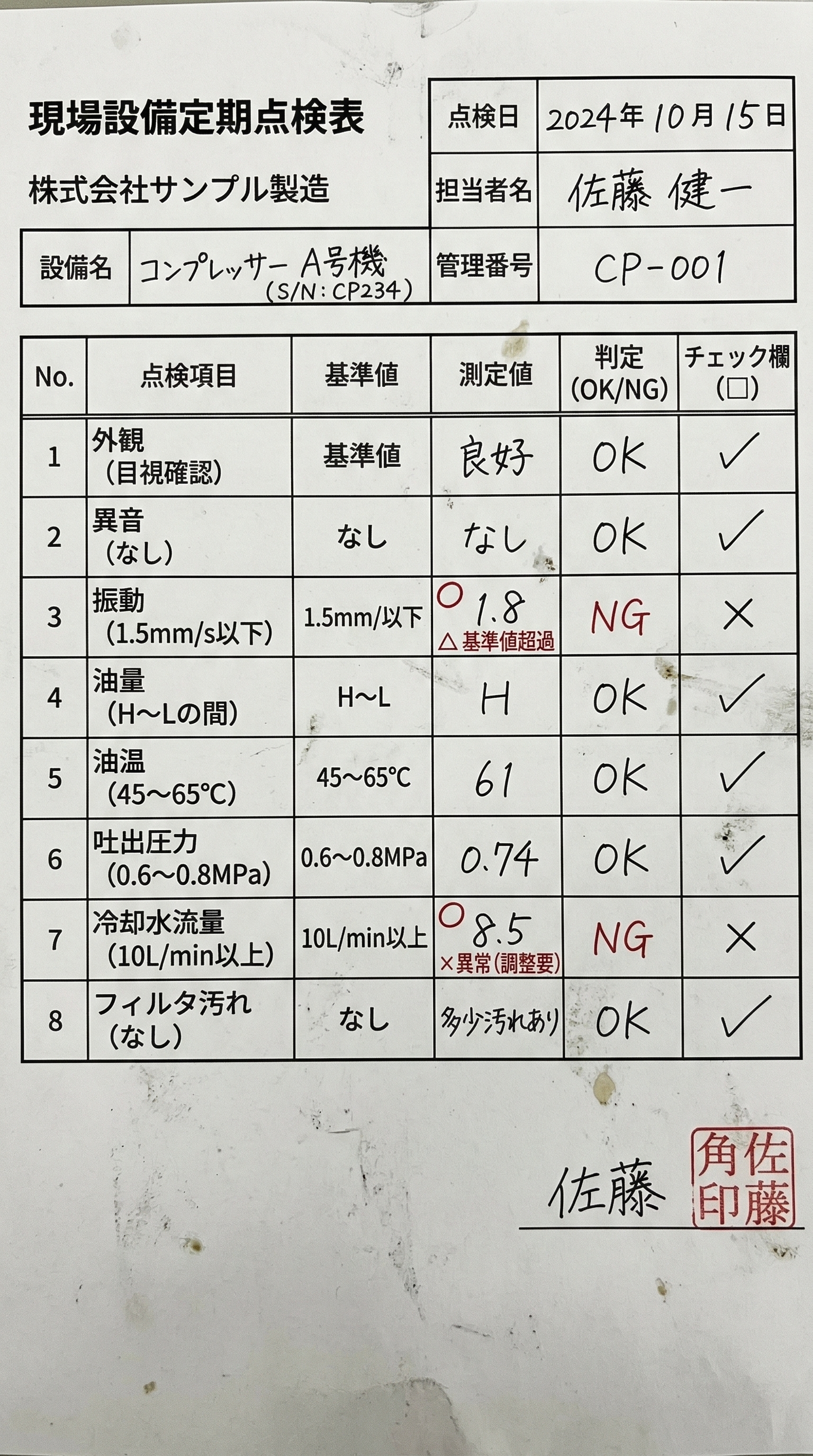
Live Demo
あらゆる文書・帳票で、
AIエージェントの処理を確認してください。
5種類の文書タブを切り替えて「処理を実行する」をクリック。 手書き点検票・CAD図面・図面シンボル・FAXなど、 従来OCRが苦手とした文書をLLMがどう処理するかを確認できます。
「処理を実行する」をクリックしてデモを開始 →
※ デモ用シミュレーションです。実際の処理はお客様文書に合わせて設計します。
Next Step
貴社の帳票種別・精度をPoCで検証する
手書き・非定型・CAD図面など、従来OCRで諦めていた文書を対象に最短2週間で検証します。
Intelligence
「読む」OCRから、
「理解する」AIへ。
多くの方がまだご存知ないかもしれませんが、最新のマルチモーダルLLMは従来のOCRとは根本的に異なります。文字を「検出」するのではなく、文書の「意味」を理解します。
TRADITIONAL OCR
文字を「検出」する
ピクセルパターンからテキストを抽出する処理。テンプレートに依存し、レイアウト変化や手書きに脆弱。認識した文字列の「意味」は理解しない。
MULTIMODAL LLM
文書を「理解」する
文書全体を視覚的に把握し、レイアウト構造・文脈・意味を同時に処理。手書きの崩し字も周辺情報から補完。「何が書かれているか」だけでなく「何を意味するか」まで推論する。
手書き文字を「読む」だけでなく「理解する」
手書きの数字・文字を認識するだけでなく、文脈から意味を補完します。「7」と「1」の判別、略字・崩し字の解釈、記入漏れ箇所の推定。従来OCRが「文字認識器」だとすれば、マルチモーダルLLMは「意味理解器」です。
APPLIES TO
非定型レイアウトにテンプレート不要
取引先ごとに異なる請求書フォーマット、バラバラな表の列構成、縦横混在のセル結合。LLMは文書の視覚的構造を人間と同様に「読み解き」、テンプレートなしで構造化データを抽出します。
APPLIES TO
「書かれていないこと」も推論する
金額の内税・外税の判断、記載単位(千円・万円)の推定、日付の表記ゆれ(令和/西暦/略記)の統一。文書に明記されていない文脈的情報を、業務ルール(SKILL.md)との照合で正確に補完します。
APPLIES TO
複数ページをまたぐ情報を統合する
1件の取引が複数ページにわたる発注書、添付書類と本文を照合する契約書、前後ページの数値を合算する明細帳票。最新LLMの長大なコンテキスト処理能力で、複数ページを一括して理解します。
APPLIES TO
The Problem
なぜ、帳票処理の
自動化は進まないのか。
AI OCRの精度はすでに実用水準に到達しています。しかし現場の大半の工数は「読み取り後」の照合・判断・例外処理に費やされています。
手書き・印刷文書の混在で、OCRが使い物にならない
現場点検票・手書き申請書・FAX注文書は、既存OCRの前処理テンプレートが対応できない。帳票種別ごとに個別設定が必要で、メンテナンスコストが際限なく膨らむ。
「読めた」後の照合・判断が手作業のまま
AI OCRで文字は読めるようになっても、マスタとの照合・金額チェック・承認ルーティングはまだ人手。自動化率が上がらず、コスト削減効果が実感できない。
CAD図面・設備記号など「特殊文書」は手つかず
製造図面の部品表、住宅平面図の設備記号、建設業の拾い出し表。これらは従来OCRが全く対応できない領域で、デジタル化が10年以上停滞している。
Use Cases
印刷物も手書きも、
あらゆる帳票・文書に対応
特に手書きが多い現場帳票・申請書類は、これまで「自動化は難しい」とされてきた領域です。
製造業:手書き現場点検票
手書き対応設備点検記録 / 品質検査票 / 作業日報
AGENT FLOW
点検票スキャン → 測定値8項目抽出 → 基準値照合・NG自動フラグ → 保全システム更新
製造業:CAD図面・部品表(BOM)
設計図面 / BOM / 改訂記録
AGENT FLOW
図面スキャン → 図番・改訂管理 → BOM全数抽出 → 手書き修正検出 → 管理システム連携
建設・ハウスメーカー:図面シンボル認識
手書き対応電気設備図 / 給排水設備図 / 平面図
AGENT FLOW
設備図受領 → 電気・給排水記号検出 → 手書き追記認識 → 拾い出し表Excel出力
全業種:社内申請書・稟議書
手書き対応購買申請 / 経費稟議 / 契約承認
AGENT FLOW
稟議書スキャン → 申請情報抽出 → 承認印判定 → 未承認者に自動通知 → ワークフロー連携
製造・卸売:FAX発注書の自動受注
FAX発注書 / 注文書 / 受注明細
AGENT FLOW
FAX受信 → 発注元・品目・数量抽出 → 合計照合 → 納期分岐検出 → 基幹システム登録
金融・法務:契約書・重要書類
売買契約書 / 覚書 / 誓約書
AGENT FLOW
契約書受領 → 当事者・金額・期日抽出 → 特記事項フラグ → 契約管理システム登録
Comparison
従来OCR・LLM単体との違い
| 比較項目 | 従来OCRツール | LLM単体 | homula Document AI Agent |
|---|---|---|---|
| 手書き文字認識 | △ 精度に限界 | △ 単体では後工程なし | ◎ 崩し字・略字も文脈補完 |
| 非定型レイアウト | × テンプレート必須 | ○ 対応可 | ◎ テンプレート不要・ゼロショット |
| 図面シンボル認識 | × 非対応 | ○ 対応可 | ◎ 建設・製造図面に特化設計 |
| CAD図面BOM抽出 | × 非対応 | △ 構造化は要カスタム | ◎ 部品表自動構造化・図番管理 |
| FAX・劣化印刷 | △ 精度低下 | ○ 対応可 | ◎ 前処理+LLMの二段構成 |
| 照合・判断(後工程) | × なし | △ 要プロンプト設計 | ◎ SKILL.mdで業務ルール完全実装 |
| 承認フロー連携 | × なし | × なし | ◎ Slack/Teams/kintone等に直接連携 |
| 閉域・セキュア構成 | ○ 可 | △ SaaS依存 | ◎ 国内リージョン閉域構成対応 |
Process
最短2週間でPoC開始。
4ステップで本番稼働へ。
キックオフ・文書種別ヒアリング
対象帳票の種別・量・現行フロー・後工程システムを整理。精度目標と例外処理ポリシーを合意します。
PoC開発・精度検証
実際の文書サンプルでパイプライン構築。読み取り精度・後工程連携の動作を測定し、ROI試算を実施。
Agent Skills実装・本番稼働
業務ルール・例外処理・承認フロー定義をSKILL.mdに実装。本番環境でパイロット稼働を開始。
運用・横展開
月次レビューで精度改善と対象帳票を拡大。社内他部門・他業務への横展開を段階的に実施。
FAQ
よくある質問
文書種別・品質・手書きの崩れ方によって異なりますが、印刷文書に近い条件では99%超、手書きが混在する現場帳票でも90〜95%以上を実現しているケースが多いです。PoCで実際のお客様文書を使った精度測定を実施してから本番判断いただけます。
n8n・Dify・LangGraphなどのオーケストレーションツールを組み合わせ、SAP・Oracle・kintone・Salesforce・SlackなどのAPIと連携設計します。既存システムへの直接書き込みやWebhook連携も対応可能です。
従来のOCRツールはCAD図面・設備記号の読み取りにほぼ対応できていません。homulaは最新マルチモーダルLLMと業務特化SKILL.mdを組み合わせ、製造図面のBOM抽出・住宅設備図面の記号認識という他社未対応の領域を実現しています。
Azure OpenAI(日本リージョン)によるVNet閉域構成、オンプレミスLLMを使ったローカル構成のいずれにも対応します。入力文書がクラウドLLMのトレーニングデータに使用されない設定も標準で適用します。
AIが判断に迷う低信頼度ケースのみ人間に通知・確認依頼する「ヒューマン・イン・ザ・ループ」設計を標準採用しています。自動処理率の目標値(通常90〜95%)と承認工数の定量目標をPoCで設定します。通常、処理件数の90〜95%以上を自動化し、残り5〜10%の例外のみ人が確認する設計を目指します。
主要帳票3〜5種を対象としたPoCは最短2週間で開始できます。費用はお問い合わせください。PoCではエンドツーエンドのパイプライン構築・精度測定・ROI試算まで実施し、本番導入の判断材料をそろえます。
Get Started
まず、御社の文書を
homulaに見せてください。
手書き点検票・CAD図面・FAX発注書など、「これは難しいのでは」と思っている文書ほど、デモの価値があります。最短2週間でPoC開始できます。